📝 Meta Description:
Learn how to create a real-time data pipeline using Apache Kafka and Apache Spark for streaming, processing, and analyzing data efficiently. A step-by-step guide with code examples.
🔑 Keywords:
Real-time data pipeline
Apache kafka tutorial
Spark streaming kafka integration
Kafka producer consumer
Big data streaming
Real-time ETL
🚀 Introduction
In a world where milliseconds matter, batch processing just doesn't cut it anymore. Companies today rely on real-time analytics to power everything from fraud detection to customer personalization.
So how do you go real-time? Enter Apache Kafka and Apache Spark — a powerful combo that can help you stream, process, and act on data as it arrives.
In this blog, we’ll build a complete real-time data pipeline that ingests data with Kafka and processes it using Spark Streaming — all with practical examples and best practices.
🧱 Architecture Overview
Let’s take a look at what we’re building:
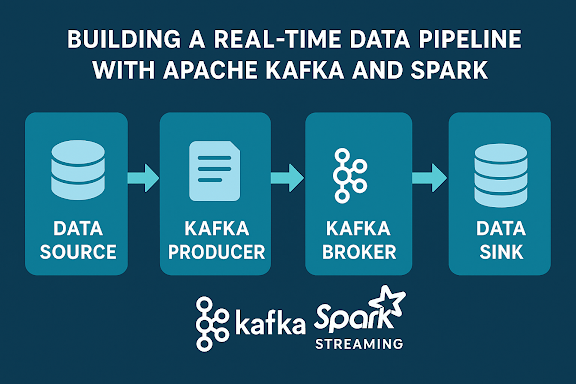
This architecture allows:
-
Decoupling producers and consumers
-
Scalable processing via partitions
-
Real-time insights from Spark

No comments:
Post a Comment